What is Video Depth Anything?
Video Depth Anything is an advanced model designed for consistent depth estimation in super-long videos. It builds upon Depth Anything V2, offering faster inference speed, fewer parameters, and higher depth accuracy compared to other models. This model can handle videos of any length without losing quality or consistency, making it ideal for applications requiring high-quality depth estimation over extended durations.
Overview of Video Depth Anything AI
| Feature | Description |
|---|---|
| AI Tool | Video Depth Anything AI |
| Category | Depth Estimation Framework |
| Function | Consistent Depth Estimation |
| Generation Speed | Efficient Processing |
| Research Paper | arxiv.org/abs/2501.12375 |
| Official Website | videodepthanything.github.io |
| GitHub Repository | github.com/DepthAnything/Video-Depth-Anything |
Video Depth Anything AI Guide
Step 1: Prepare the Environment
Action: Clone the repository and install the necessary dependencies.
What Happens: This sets up the environment needed to run Video Depth Anything. Use the following commands:
git clone https://github.com/DepthAnything/Video-Depth-Anything
cd Video-Depth-Anything
pip install -r requirements.txt

Step 2: Download Checkpoints
Action: Download the model checkpoints and place them in the correct directory.
What Happens: This ensures the model has the necessary data to perform depth estimation. Use the command:
bash get_weights.sh
Step 3: Run Inference
Action: Execute the script to process your video and estimate depth.
What Happens: The model processes the video and outputs the depth estimation. Use the command:
python3 run.py --input_video ./assets/example_videos/davis_rollercoaster.mp4 --output_dir ./outputs --encoder vitl
Key Features of Video Depth Anything
Consistent Depth Estimation
Ensures stable and consistent depth estimation across super-long videos, maintaining quality without sacrificing efficiency.
Efficient Spatial-Temporal Head
Utilizes an efficient spatial-temporal head to process videos, allowing for faster inference speeds and fewer parameters.
Temporal Consistency Loss
Introduces a simple yet effective temporal consistency loss to maintain depth accuracy without additional geometric priors.
Key-Frame-Based Strategy
Implements a novel key-frame-based strategy for long video inference, ensuring consistent depth estimation over time.
Real-Time Performance
Offers models of different scales, with the smallest model capable of real-time performance at 30 FPS.
State-of-the-Art Results
Achieves state-of-the-art results in zero-shot video depth estimation, demonstrating superior performance on multiple benchmarks.
Examples of Video Depth Anything in Action
1. Long Video Results
Video Depth Anything excels in handling long-duration videos without losing depth accuracy. The example shows a cyclist moving through varied terrains, demonstrating the model's robustness in maintaining consistent depth perception over extended sequences.
2. Play Speed x3
This example highlights the model's capability to process videos at increased speeds. The silhouette of a cyclist against a dynamic background showcases how Video Depth Anything maintains depth accuracy even when the video play speed is tripled, ensuring reliable performance under different viewing conditions.
3. Enhanced Depth Perception
Video Depth Anything provides enhanced depth perception across various scenarios. It is particularly effective in scenes with complex movements and varying backgrounds, ensuring that depth estimations are accurate and consistent throughout the video. For instance, as shown in the accompanying images, the model accurately differentiates depth in a complex urban environment and provides detailed depth maps in thermal imaging scenarios, highlighting its robustness and versatility.
Pros and Cons of Video Depth Anything
Pros
- Consistent depth
- Faster inference
- Efficient parameters
- Accurate depth
- Real-time 30 FPS
- Joint dataset training
- Key-frame strategy
Cons
- Quality dependent
- High resource need
- Variable performance
- Model-specific downloads
How to Use Video Depth Anything AI using github?
Step 1: Clone the Repository
Clone the Video Depth Anything repository from GitHub and navigate into the directory using the following commands:
git clone https://github.com/DepthAnything/Video-Depth-Anything
cd Video-Depth-Anything
Step 2: Install Dependencies
Install the required Python dependencies by running:
pip install -r requirements.txt
Step 3: Download Pre-trained Weights
Download the pre-trained model weights with the provided script:
bash get_weights.sh
Step 4: Run Inference on a Video
Perform depth estimation on your video by executing the inference script:
python3 run.py --input_video ./assets/example_videos/davis_rollercoaster.mp4 --output_dir ./outputs --encoder vitl
You can adjust various options such as input size, resolution, and encoder type as needed.
Step 5: Review and Use Output
Check the output directory for the depth estimation results, which can be used for further processing or analysis.
How to Use Video Depth Anything AI on Hugging Face?
Step 1: Upload Your Video
Navigate to the Hugging Face model page and use the upload section to select and upload your video file.
Step 2: Adjust Advanced Settings
Optionally adjust the advanced settings such as target FPS, resolution, and other parameters according to your needs.
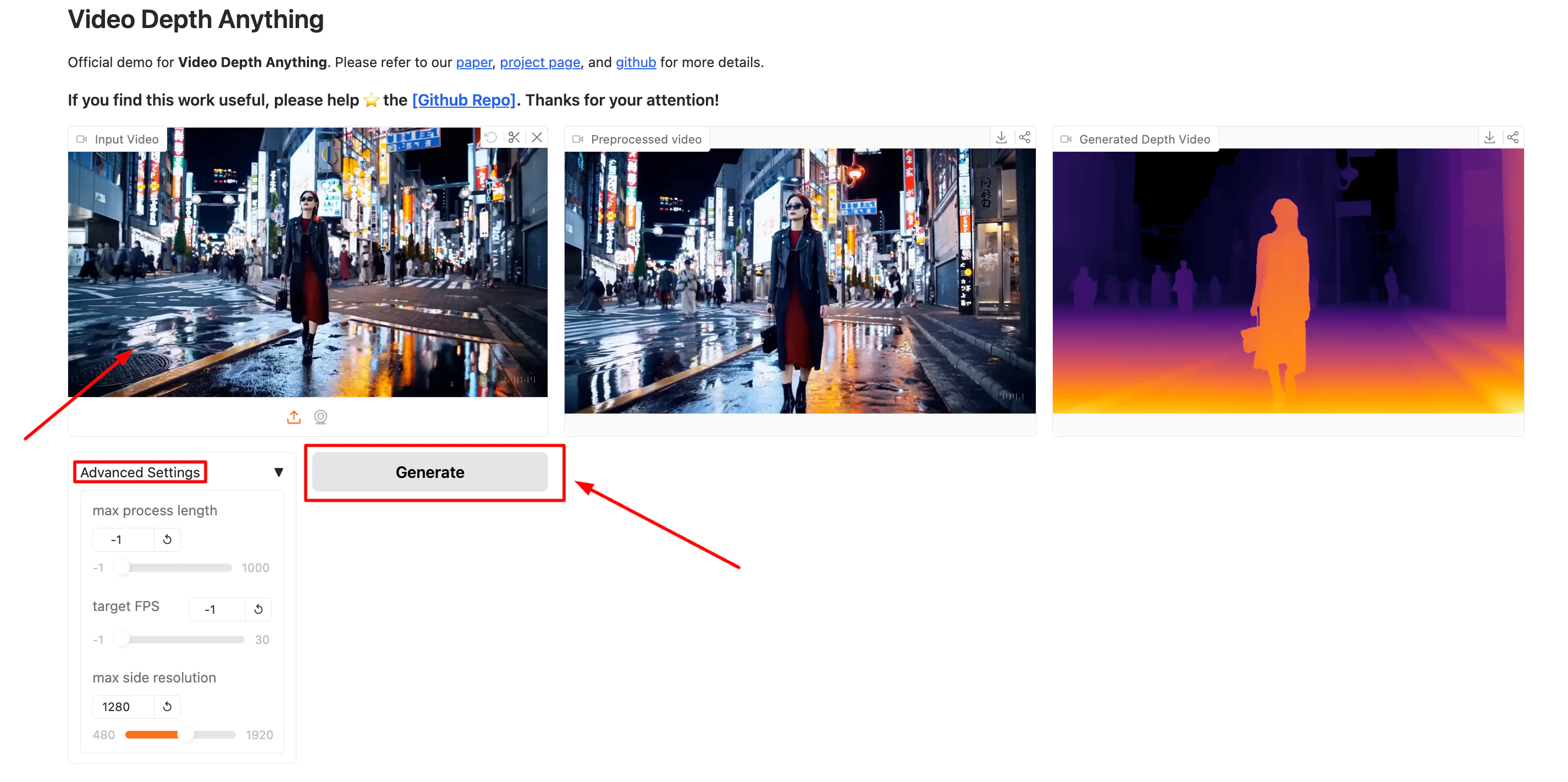
Step 3: Generate Depth Map
Click the 'Generate' button to start the process of depth estimation. The model will process the video and generate a depth map.
Step 4:Review the Output
Once the depth map is generated, you can directly use the output for your applications.